
Embeddings power many AI applications we interact with — search engines, RAG systems — but how do we know if they’re actually any good? Existing benchmarks tend to focus on a narrow set of tasks, often evaluating models in isolation without considering real-world, multilingual challenges. This can make it tough to figure out which models are truly effective, and where they might fall short. That's why we need a more comprehensive way to evaluate embeddings - one that takes into account the messy, multilingual nature of real-world language use. MMTEB is designed to fill this gap, providing a broad and diverse set of evaluation tasks that can help us better understand what works, and what doesn't, in the world of embeddings.
- What is MMTEB?
- What are the key takeaways from MMTEB?
- How can I use MMTEB?
What is MMTEB?
The Massive Multilingual Text Embedding Benchmark (MMTEB) is an extension to the existing Massive Text Embedding Benchmark (MTEB), a comprehensive evaluation framework for assessing the performance of text embedding models. MTEB was introduced in 2022 as a way to evaluate embeddings models in a single, unified benchmark. The MTEB leaderboard has since been a popular destination for many to gauge embedding model performance using the average score across all tasks. MMTEB takes this a step further by covering over 500 quality-controlled evaluation tasks across 250+ languages, making it the largest multilingual collection of evaluation tasks for embedding models to date.
MMTEB introduces a diverse set of challenging, novel tasks that test the capabilities of embedding models in real-world scenarios. These tasks include:
- Instruction following: This task evaluates a model's ability to understand and execute instructions, such as answering questions or generating text based on a given prompt.
- Long-document retrieval: This task assesses a model's ability to retrieve relevant information from long documents, such as articles, reports, or books.
- Code retrieval: This task tests a model's ability to retrieve relevant code snippets or software documentation based on a given query or prompt.
What are the key takeaways from MMTEB?
Performance Varies Widely Across Languages – MMTEB highlights that models like all-MiniLM-L6 and all-mpnet-base perform well in English but see sharp performance drops in low-resource languages. Some models even fail completely on certain languages, revealing critical gaps in multilingual generalization.
Generalization is a Challenge – MMTEB introduces new task types like long-document retrieval and instruction following, where many leading models struggle. E.g. embedding models trained primarily on short text often fail to retrieve relevant long documents, demonstrating their limited adaptability to new task formats.
Bigger Isn’t Always Better – The multilingual-e5-large-instruct model outperforms Mistral-based models in several benchmarks like MTEB(Europe), despite the latter being a larger model. This suggests that smaller, well-optimized multilingual models can generalize better across languages than larger models that are not explicitly fine-tuned for diverse multilingual tasks.
Here is the bottom line: As the world becomes more connected, ML systems must perform across languages, not just English. However, most languages are "left-behinds" with limited online presence and resources, creating a "low-resource double bind". To address this, MMTEB aims to make it easier to evaluate embeddings on diverse languages while minimizing computational resources, and help bridge the gap for low-resource communities, a challenge highlighted by Ivan Vulic's ECIR 2022 keynote.
So what does it mean for you?
For practitioners: This shifts how we should think about embedding models. Instead of defaulting to the latest or most hyped model, it’s now possible to select embeddings based on real, task-specific performance. If you're building a semantic search system, MMTEB provides insights into which models excel at retrieval and reranking. If you’re working with multilingual data, you can see which embeddings actually handle cross-lingual retrieval. This kind of benchmarking isn’t just useful — it’s essential for making informed choices in production AI systems.
This also has implications for businesses adopting AI-powered solutions. Many companies rely on third-party embedding models for recommendations, knowledge retrieval, or search, but without proper benchmarking, it's easy to pick a model that underperforms in critical areas. MMTEB provides a clear, objective way to evaluate models before committing to them, reducing the risk of investing in suboptimal solutions. Whether you're fine-tuning an open-source model or evaluating commercial offerings, this benchmark helps cut through the noise and focus on what actually works.
For researchers: MMTEB sets a new standard for embedding evaluation. Instead of optimizing for isolated benchmarks, model development can now be guided by a diverse set of real-world tasks, encouraging progress in areas where embeddings still fall short. It also opens up new questions: How can we build embeddings that perform well across languages without sacrificing efficiency? What trade-offs exist between generalization and specialization? As more models are tested against MMTEB, we’ll gain a clearer picture of what’s working, what’s not, and where the field needs to go next.
How can I use MMTEB?
MMTEB is available in the MTEB repository on GitHub and provides a structured way to evaluate embedding models across a wide range of multilingual tasks.
To get started with MMTEB, you can install the mteb library using pip:
pip install mteb
Next, you can use the library to run your model against MMTEB's 500+ evaluation tasks.
Benchmark Your Model: For example, you can run the new English benchmark, which uses 2% of the original number of documents while maintaining rankings.
import mteb
# Load a pre-trained model. The model weights will be downloaded.
model = mteb.get_model("intfloat/multilingual-e5-small")
# Load a benchmark or tasks.
benchmark = mteb.get_benchmark("MTEB(eng, v2)")
# Create an evaluation object
evaluation = mteb.MTEB(tasks=benchmark)
# Run evaluation. The datasets will be downloaded at this step. Results are written to disk.
results = evaluation.run(model)
You can also task-specific scores to see where your model excels (e.g. retrieval, classification) and where it struggles (e.g., low-resource languages, long-document retrieval). For more details, please refer the repository's README file.
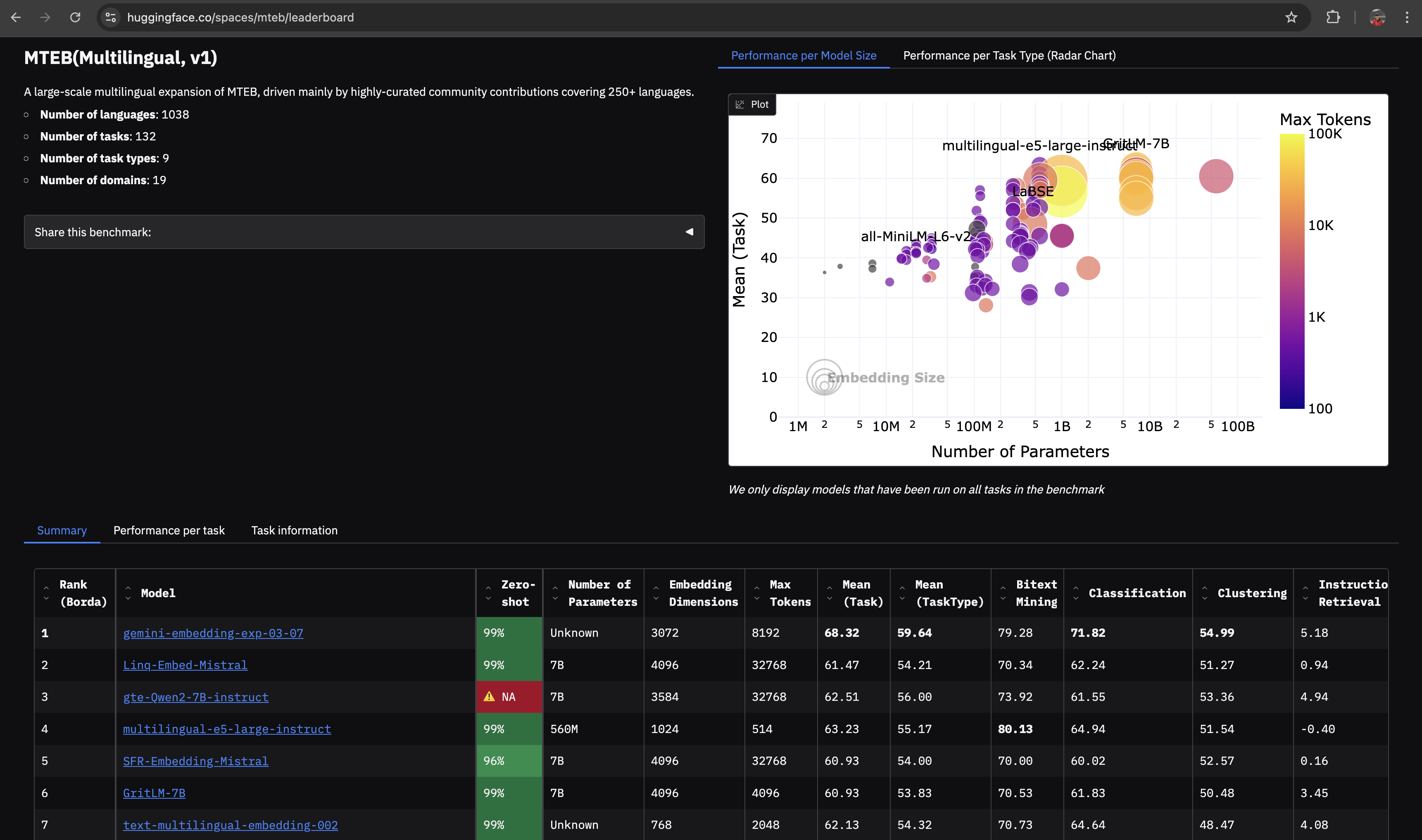
Compare Against State-of-the-Art: The MMTEB leaderboard lets you see how your model stacks up against top-performing multilingual embeddings. The MMTEB leaderboard ranks models using the Borda count method, a voting system that assigns points to each model based on its performance across all evaluation tasks. This way, the top-performing model receives the most points, the second-best model receives fewer points, and so on. The model with the highest total score across all tasks is ranked highest on the leaderboard. The Borda count method is used to provide a more nuanced ranking that takes into account a model's performance across multiple tasks, rather than just its average score.
The "Zero-Shot" column on the MMTEB leaderboard indicates the percentage of evaluation datasets that did not have their training split used to train the model. In other words, it measures how well a model performs on tasks it has not seen during training, without any fine-tuning or additional training data. A higher "Zero-Shot" score means that the model is more capable of generalizing to new, unseen tasks, which is a key aspect of real-world applicability. This metric is important because it helps evaluate a model's ability to adapt to new scenarios and tasks, rather than just memorizing patterns in the training data.
So what's next? Try out MMTEB and see how your models stack up. If you hit any roadblocks, open an issue. And if you're able, consider contributing to help us make MMTEB even better.